
Investigating the (often dubious) dealings of businessmen and politicians, our reporters need access to documents and databases from all over the world.

To make their searches better, we're developing tools that make large amounts of data accessible with a single keystroke. We have built a set of crawlers that combine data from governments, corporations and other media into a search engine.
However, these crawlers need to deal with uncooperative websites in different languages, formats and structures and they often break when pages are updated.
After experimenting with some existing solutions, we decided to make a
tool that encapsulates our experience with web crawling. The result is a
lightweight open source framework named memorious
(GitHub).
memorious is simple and yet allows you to create and maintain a fleet
of crawlers, while not forcing too much specific process.
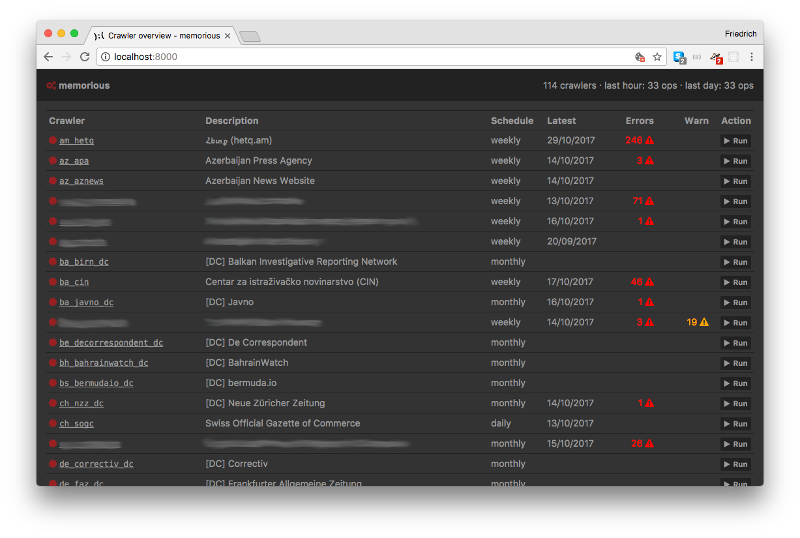
- Schedule crawlers to run at regular intervals (or run them ad-hoc as you need).
- Keep track of error messages and warnings that help admins see which crawlers are in need of maintenance.
- Lets you use familiar tools like
requests,BeautifulSoup,lxmlordatasetto do the actual scraping. - Distribute scraping tasks across multiple machines.
- Maintain an overview of your crawlers' status using the command line or a web-based admin interface.
For common crawling tasks, memorious does all of the heavy lifting. One
of our most frequent objectives is to follow every link on a large website and
download all PDF files. To achieve this with memorious, all you need to write
is a YAML file
that plugs together existing components.
Each memorious crawler is comprised of a set of different stages that call each
other in succession (or themselves, recursively). Each stage either executes a
built-in component, or a custom Python function, that may fetch, parse or store a
page just as you like it. memorious is also extensible, and contains lots of
helpers to make building your own custom crawlers as convenient as possible.
These configurable chains of operations have made our crawlers very modular, and common parts are reused efficiently. All crawlers can benefit from automatic cookie persistence, HTTP caching and logging.
Within OCCRP, memorious is used to feed documents and structured data into
aleph via an API, which means documents
become searchable as soon as they have been crawled. There, they will also
be sent through OCR and entity recognition. aleph aims to use these extracted
entities as bridges that link a given document to other databases and documents.
For a more detailed description of what memorious can do, see the
documentation and check out our
example project.
You can try memorious by running it locally in development mode,
and, of course, we also have a Docker setup for robust production deployment.
As we continually improve our crawler infrastructure at OCCRP, we'll be adding
features to memorious for everyone to use. Similarly, we'd love input from the data
journalism and open data communities; issues
and PRs are welcome.
“…the solitary and lucid spectator of a multiform, instantaneous and almost intolerably precise world…” (Funes the memorious, Jorge Luis Borges)