
Come for the company formation. Stay for the beaches!
11.06.2018, by Jason SheaWho Watches the Wealthy
Tracing the realtime movements of most ordinary commercial and private aircraft can be straightforward through ‘tracking’ websites :

These sites collect signals from a public high-frequency radio band, primarily for use by air-traffic control systems and other aircraft, known as the ADS-B system. ADS-B signals can be monitored with any appropriately tuned antenna – you can make one at home (see below)!
These methods allow anyone to follow common flights with only some basic identifying information - unless the owner of the plane is powerful, wealthy, or motivated enough to have their aircraft data redacted.
If you’re a journalist, and the subject of your story has done exactly that - then what?
OCCRP has a solution.
Our data team has coordinated with ADSB-Exchange and C4ADS, which jointly collects and manages the world’s largest source of unfiltered flight data, to examine the travels of a host of oligarchs and political leaders.
Here is how it works.
The Data Trail in Five Minutes
Receivers in this co-operative network record the aircraft position, speed, altitude, and timestamp, all signed with an ‘address’ known as an ICAO address or Mode-S code, which uniquely identifies the aircraft.
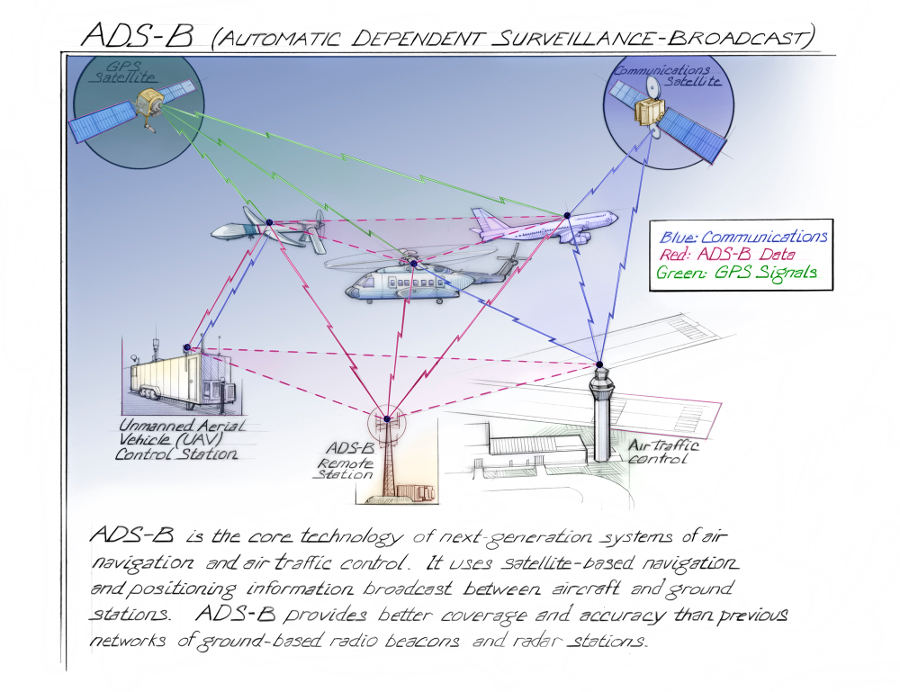
The receivers have a maximum range of around four hundred kilometers and are located mostly on densely populated landmasses. This also means that planes flying over places like the Atlantic or the Sahara, for example, will sometimes leave the network’s range entirely.
Other obstacles to assembling a clear picture occur when an aircraft descends under the effective altitude for signal transmission — predominantly to land — or when overlapping signals are detected by multiple receivers.
Any attempt to piece together a picture of the travels by hand will be complex and painstaking, since one aircraft can easily generate over fifty thousand position readings over a two year period.
To assemble readings that constitute distinct flights, OCCRP’s data team has designed a small collection of data analysis algorithms which, among other things, group observations of any aircraft across multiple antennae by timestamp and infer takeoff & landing through a combination of first & last position relative to major airports and aircraft altitude at the time.
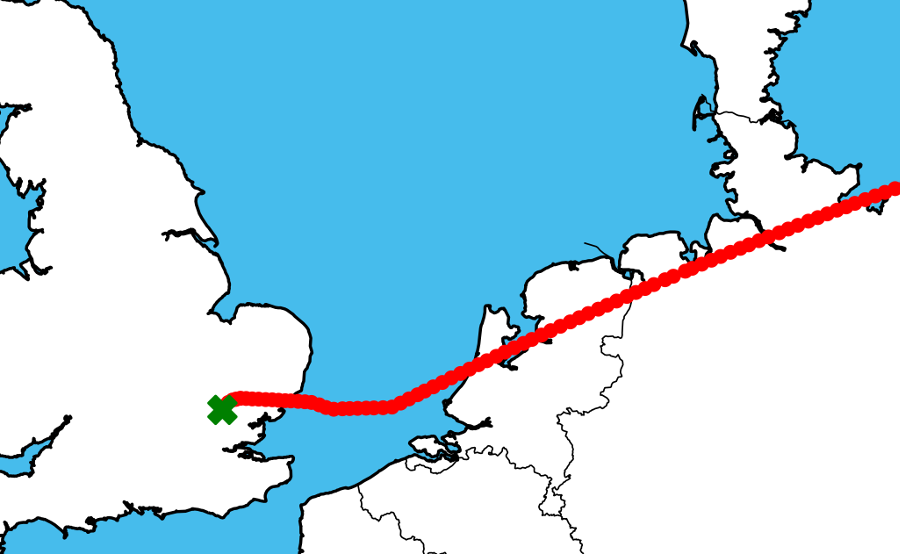
For example, if a collection shows an aircraft’s final position reading for (at least) many hours near London Heathrow at a low altitude, our algorithm assumes it’s landed there.
If we find the last reading at a high altitude above the North Atlantic off the Irish coast, with readings resuming after a couple of hours above Iceland, we stitch the two sets of positions together.
Flight data from this network should not be considered complete. In many parts of the world, including many potential regions of interest, the available receivers may be few and far apart, and the sparse data can force a ‘best guess’ methodology for projecting what airport the aircraft is departing from or arriving to.
In some cases, an aircraft’s signal is seen to disappear over an ocean and isn’t seen for weeks due either to staying grounded, out of the network’s coverage area or potentially deactivating its’ transponder.
After observations are algorithmically grouped into distinct flights, we can zoom in on interesting travels by ‘geofencing’ destinations of interest, selecting all flights by aircraft of interest whose flight endpoints fall within range of select airports.
In one example, Cyprus, long described as a gateway into Europe for Russian money, has seen many interesting visitors (each oligarch has his own color!... see below for details).
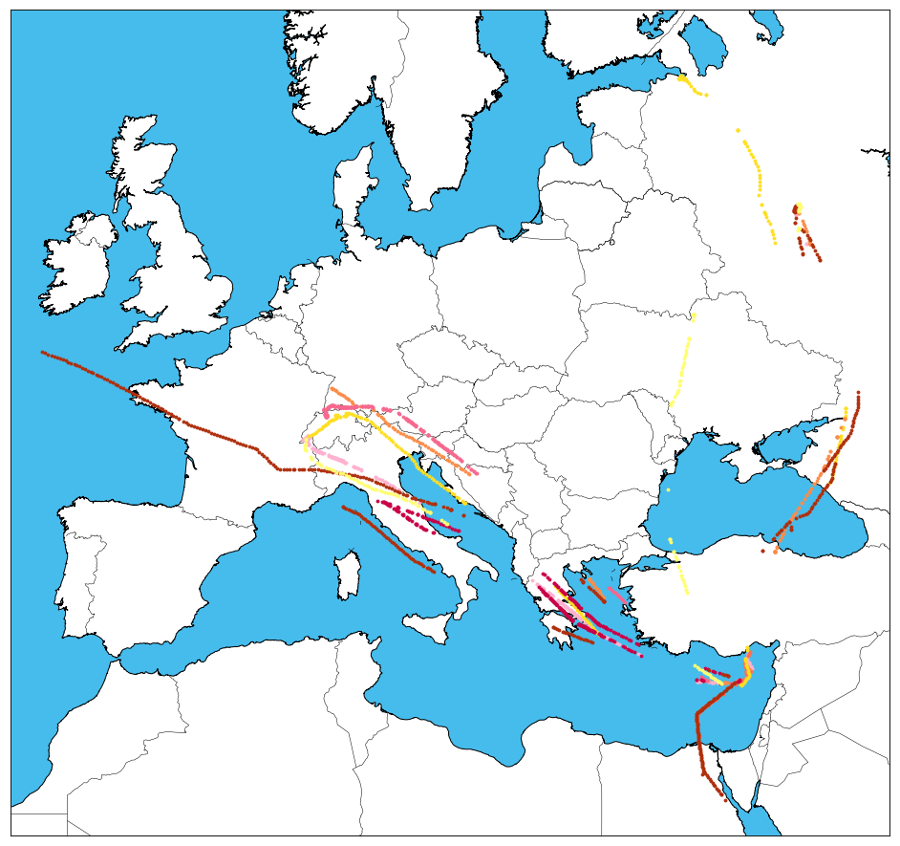
While the wealthy and powerful travel European capitals and the exclusive resorts of the ultra-rich quite frequently, insight into their travels goes well beyond Monaco and Sochi, and visits to more tropical climates may prove of greater interest.
OCCRPs’ initial analysis has centered on sunny money laundering hubs including the British Virgin Islands, Cyprus, or Panama City, as well as the considerably less sunny Isle of Man. As a brief introduction to how these destinations might be of interest, look no further than OCCRP's own reporting on two huge global operations, The Panama Papers and The Russian Laundromat.
Come for Company Formation, Stay for the Beaches
Let’s look deeper at just one example of how our tracking works.
Roman Abramovich’s expensive tastes is famous and it would be uncouth for such a man to travel on a commercial airline. As might be expected, Mr. Abramovich maintains a sleekly decorated Boeing 767, among other jets, to carry him in comfort and style.
Like most aircraft, Mr. Abramovich’s Boeing regularly, though not always, transmits its location along with various other data on the so-called ADS-B system which the usual tracking websites collect.
Curious about his travels, we can input the tail number of the 767, visible from photographs as ‘P4-MES’, into one of those sites but we would find no records of the aircraft's travels, as presumably they have been redacted.
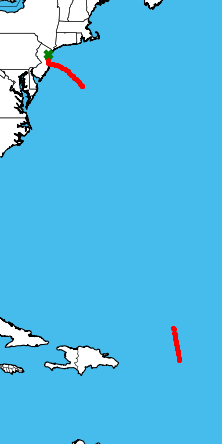
If we checked in at the right time, we can monitor his plane in realtime on the ADSBExchange site. Many times a month, Abramovich’s Boeing flies between Moscow and London - unsurprising given his well-known business interests in both capitals. He frequents St. Petersburg and New York as well and makes regular appearances in Monaco, Sochi, and the Black Forest in Germany. Recently, in pursuit of his newly acquired Israeli citizenship, he’s flown multiple times to and from Tel Aviv.
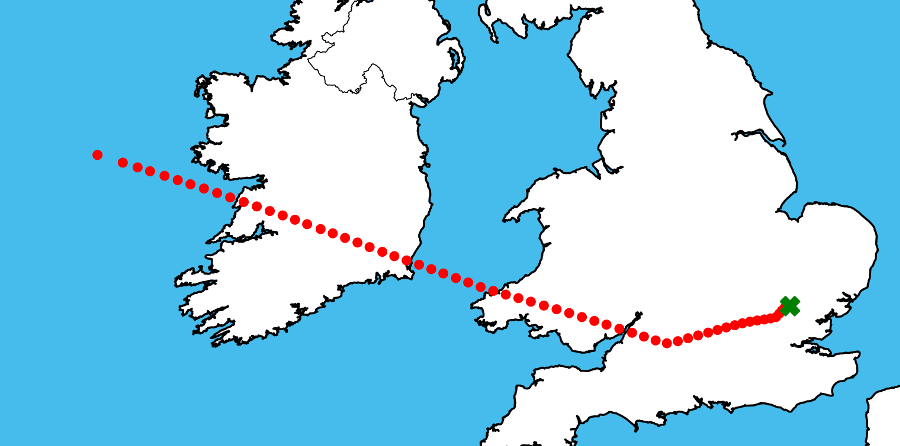
Among these more common travels, we know Mr. Abramovich’s jet visited the area of the British Virgin Islands several times in early 2017, including this trip (pictured right) from New Jersey on February 17 2017. He stayed there until February 27. Similar trips occured on January 3, and March 24, and December 22.
OCCRP alleges no illegal activity by Mr. Abramovich or any of the other billionaires detailed below, only that they are frequent fliers to certain locations.
Indeed, are billionaires not allowed to soak in long sea-breeze days on the beach along with the rest of us who can afford to step foot in these exclusive communities? One imagines these evenings, enjoying a bottle of 1780 Barbados Private Estate, watching a small army of dolphins trained for exclusive entertainment from the comfort of a glass-walled swimming pool levitating peacefully above a peach-hued bay.
It might just be of interest to see if any companies were registered during these afternoons.
British Virgin Islands Company Gazette
Boyars in Paradise (and the Irish Sea)
OCCRP has initially examined 35 aircraft of interest flying more than 7.5 million kilometers over some 5800 flights. This analysis has uncovered trips to known money laundering resorts from a number of notable figures including:
- Alexander Abramov : Russian steel magnate, chairman of Evraz Group.
- Alexander Mashkevitch : Kazakh-Israeli businessman and major shareholder in Eurasian National Resources Corporation.
- Alexei Mordashov : Russian owner of Severstal.
- Alisher Usmanov : Uzbek-Russian industrial magnate and investor.
- Andrey Guryev : Dominant in the Russian fertilizer industry; beneficial owner of PhosAgro.
- Dmytro Firtash : Ukranian businessman and ally of the Yuschenko & Yanukovich administrations. US currently seeking extradition.
- Farkhad Akhmedov : Azeri-Russian businessman and politician.
- Igor Makarov : Turkmen-Russian businessman, owner of ARETI International Group.
- Len Blavatnik : Soviet-born British-American diversified businessman. Active in American politics and longtime friend of Viktor Vekselberg.
- Leonid Mikhelson : Owner of Russian gas company Novatek and subject to US sanctions.
- Oleg Tinkov : Russian diversified businessman and founder of Tinkoff Bank.
- Roman Abramovich : Russian diversified businessman, philanthropist, and owner of Chelsea FC.
| Aircraft Owner | Date | Origin | Destination |
|---|---|---|---|
| Alexander Abramov | 12/5/2016 | Van Nuys, USA | Anegada, British VG |
| Alexander Abramov | 2/6/2017 | Houston, USA | Anegada, British VG |
| Alexander Abramov | 2/23/2017 | Miami, USA | Anegada, British VG |
| Alexander Mashkevitch | 12/16/2017 | Isle of Man | London, UK |
| Alexander Mashkevitch | 2/25/2018 | London, UK | Panama City, Panama |
| Alexander Mashkevitch | 4/11/2018 | Panama City, Panama | Punta Cana, Dominican Republic |
| Alexei Mordashov | 5/10/2017 | Isle of Man | London, UK |
| Alisher Usmanov | 2/20/2018 | Larnaca, Cyprus | Mulhouse, France |
| Andrey Guryev | 8/13/2016 | Unknown in Greece | Paphos, Cyprus |
| Dmytro Firtash | 3/25/2017 | Unknown in South Pacific | Auckland, NZ |
| Farkhad Akhmedov | 1/17/2017 | Spanish Town, British VG | Miami, USA |
| Igor Makarov | 7/14/2016 | Paphos, Cyprus | Unknown in France |
| Igor Makarov | 10/12/2016 | Unknown, North Atlantic | Nicosia, Cyprus |
| Igor Makarov | 10/15/2016 | Cairo, Egypt | Larnaca, Cyprus |
| Len Blavatnik | 12/29/2016 | San Juan, Puerto Rico | St. Thomas, Virgin Islands |
| Len Blavatnik | 4/9/2017 | Alice Town, Bahamas | Anegada, British VG |
| Leonid Mikhelson | 9/25/2016 | Akrotiri, Cyprus | Strasbourg Neudorf, France |
| Oleg Tinkov | 4/27/2018 | Florence, Italy | Larnaca, Cyprus |
| Roman Abramovich | 1/3/2017 | New Jersey, USA | Anegada, British VG |
| Roman Abramovich | 3/24/2017 | Denver, USA | Anegada, British VG |
Investigative curiosities from the jet-setting frontier don’t stop at money laundering. Witness Mr. Abramovich on 3-9-18, flying (it appears) from Crimea / Rostov-on-Don area, amusingly looping the hundreds of kilometers all the way round Ukrainian airspace, to London.
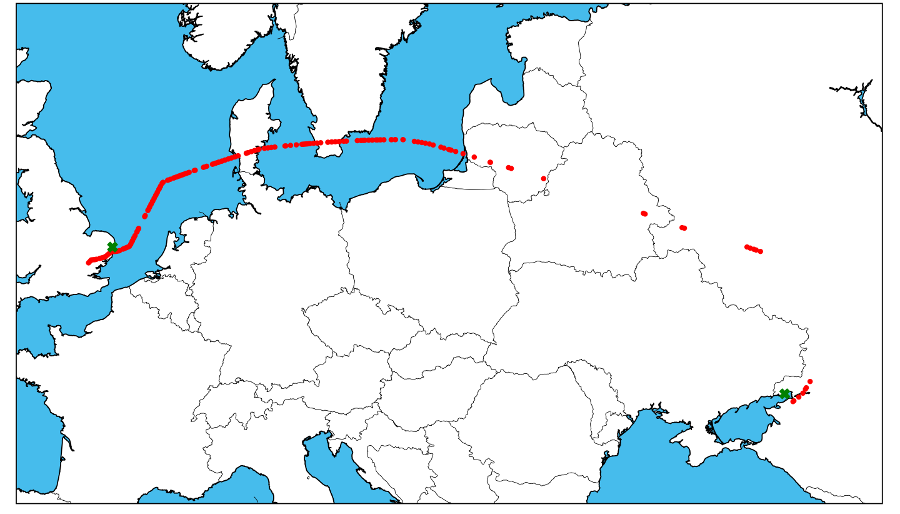
Or his visit to the Iranian island oil and gas outpost of Sirri on January 28 2018...or perhaps the government of Equatorial Guinea ferrying honest public servants to Singapore, Mykonos, Mytilini, Winnipeg, Los Angeles, and Rio de Janeiro might interest you.
These findings are only the beginning. We encourage interested journalists to contact data@occrp.org with research requests and feedback on our analysis. We want to hear from you! We also encourage you to reach out to ADSB-Exchange (https://www.adsbexchange.com/contact/) or C4ADS (info@c4ads.org) for more information about the flight data network and how you can help.
Food for thought:
- With the help of OCCRP Research, Data Team has compiled a long list of 'interesting' aircraft from the oligarchs above to the Saudi Royals. Let us know who you're looking for.
- Should we publish a weekly digest of the movements of select aircraft or travel into certain locations?
- Can we identify events whose airborne attendees we could study?
- If you had access to a web resource which allowed you to browse the travels of select aircraft or ownership organizations (think ‘Azerbaijan Airlines’ or other pseudo-governmental carriers), how would you use it?
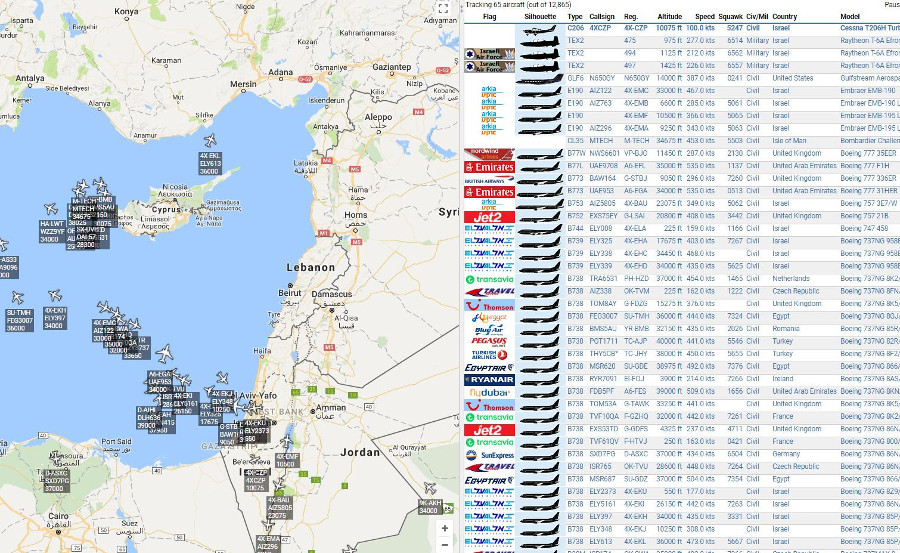
- A live version of the ADSB Exchange tracking network is always viewable (sceen below)
- Additionally, if you would like to check out historical flight data for an aircraft of interest, be sure to check out ADSB-Exchange’s historical flight viewer.
Thanks to:


- ADSB 'Can' Receiver courtesy www.adsbexchange.com
- ADSB System Illustration courtesy The National Air and Space Museum, Smithsonian Institution
- All aircraft-tracking maps generated with 'Basemap' https://github.com/matplotlib/basemap
Journalism’s Deep Web: 7 Tips on Using OCCRP Data
13.04.2018, by Stella Roque, Iain Collins, and Friedrich Lindenberg
This article was first published on GIJN.org.
The Organized Crime and Corruption Reporting Project (OCCRP) Data Team has developed new features on OCCRP Data in the past six months and brought together more than 200 different datasets. Its new software is now configured to let reporters search all of those at once.
OCCRP Data, part of the Investigative Dashboard, offers journalists a shortcut to the deep web. It now has over 170 public sources and more than 100 million leads for public search – news archives, court documents, leaks and grey literature encompassing UK parliamentary inquiries, companies and procurement databases, NGO reports and even CIA rendition flights, among other choice reading. (All this is publicly available. If you’re associated with OCCRP, you’ll have access to more than 250 million items).
Uniquely, the database also contains international sanctions lists detailing persons of political or criminal relevance.
The new platform makes searching diverse types of objects, such as emails, documents and database entries from corporate or land registries into a unified user experience, with an appropriate way to display each type of data.
Here are seven tips to help you get the most out of OCCRP Data:
Browse Directly on Your Screen
OCCRP Data has emails, PDF and Word documents, contracts, old news archives, even Rudyard Kipling poems (from Wikileaks, to be fair). Its brand new interface makes it easier for you to view documents, search within them and preview them in the browser without having to download and open them, making research a faster and more seamless process.
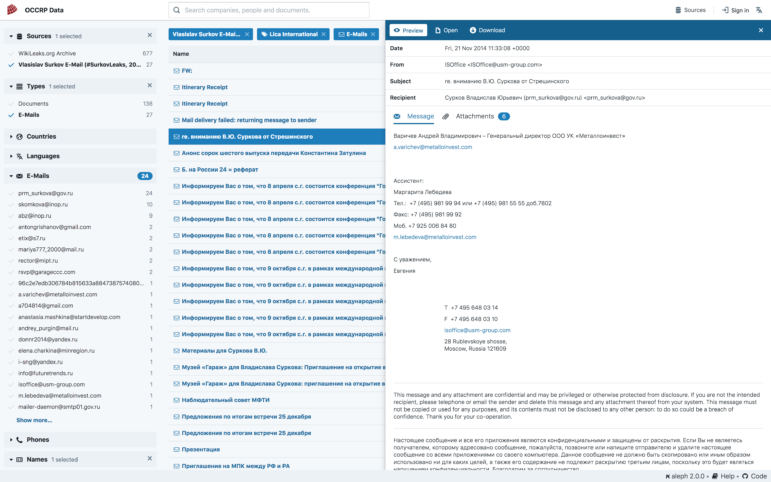
New Search Filter Options
OCCRP Data lets you filter search results by sources, document type, as well as emails, phone numbers, addresses, entity names, countries and more on its left-hand column, after you’ve run your search.
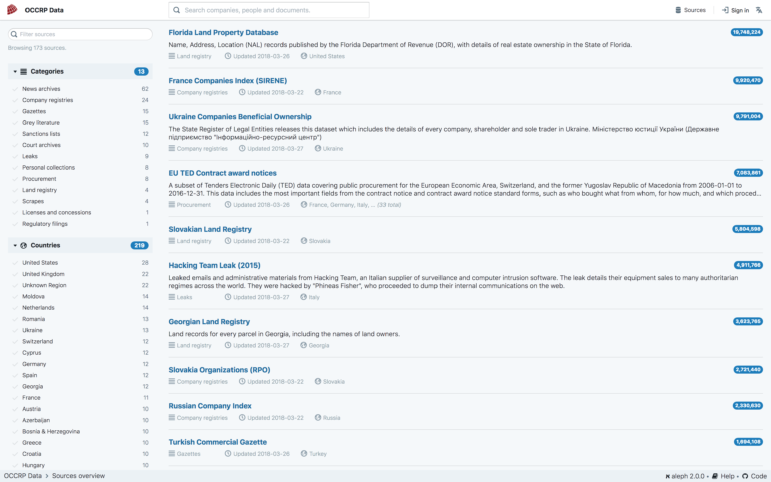
Highlight Connections
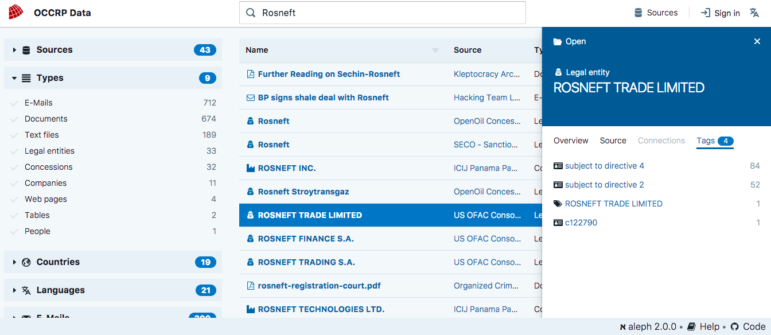
You can explore structured data in new ways because OCCRP Data uses entity extraction on documents and emails to find phone numbers, names of people and companies, addresses, ID numbers and other key linkage details of interest. Just click on an entity and see the “Tags” option in the preview screen.
Do Bulk Comparisons
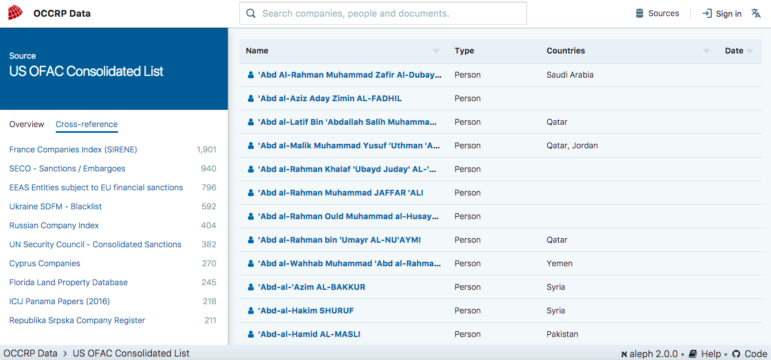
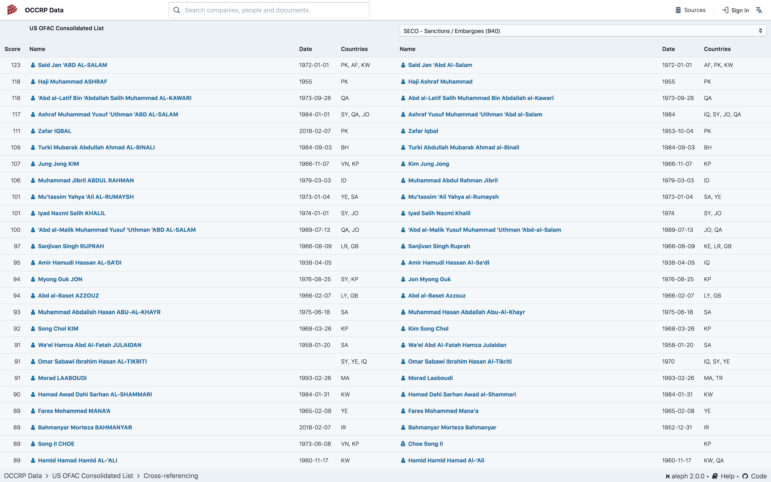
OCCRP Data is capable of cross-referencing the information on two lists; it also ranks data that closely matches and lets you compare the information. Click on a source and then click on the “Cross Reference” option to choose another source with which to do the comparison.
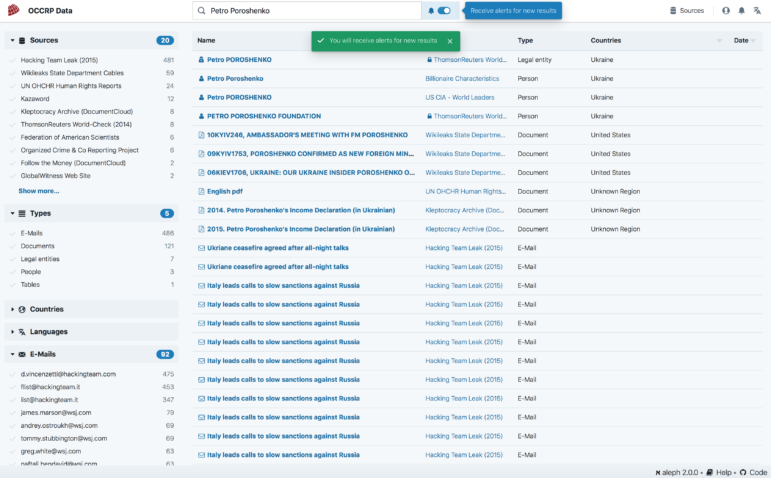
Monitor Search Terms, Receive Alerts
OCCRP Data now has an alerts feature that allows you to monitor a search term so when new information is added to the database you will receive a notification. Simply switch on the bell icon right next to your search query.
Language Support
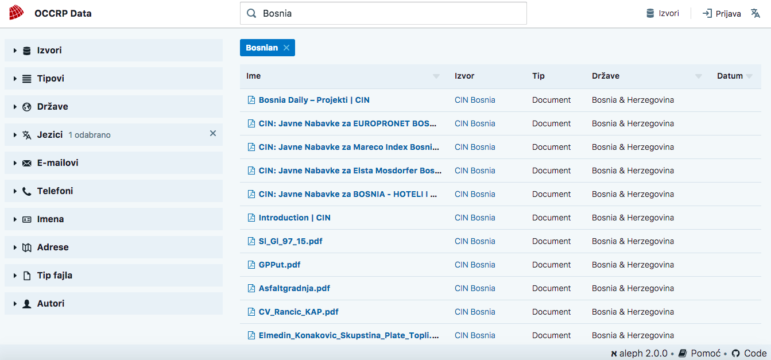
OCCRP Data now supports multiple languages. The interface is translated and supports Russian and Bosnian-Serbo-Croatian. Search results on the database can also be filtered by language. The data team is working on adding other languages, such as German and Spanish.
Advanced Search Operators
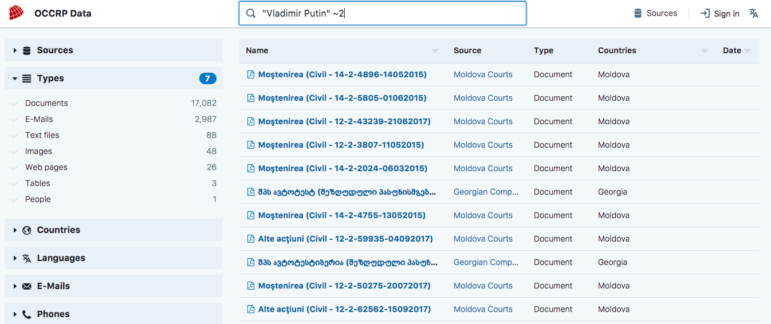
You can use complex search operators to do things such as proximity searches, exact term searches, take into account spelling errors and combine queries.
Any Questions?
Anyone accessing OCCRP Data can check out the the Aleph Wiki where the data team covers its uses, function and development roadmap. Journalists and technologists alike can read the user manual or contact data@occrp.org to give us feedback.
Introducing memorious, a web crawling toolkit
21.11.2017, by Amy Guy and Friedrich LindenbergInvestigating the (often dubious) dealings of businessmen and politicians, our reporters need access to documents and databases from all over the world.

To make their searches better, we're developing tools that make large amounts of data accessible with a single keystroke. We have built a set of crawlers that combine data from governments, corporations and other media into a search engine.
However, these crawlers need to deal with uncooperative websites in different languages, formats and structures and they often break when pages are updated.
After experimenting with some existing solutions, we decided to make a
tool that encapsulates our experience with web crawling. The result is a
lightweight open source framework named memorious
(GitHub).
memorious is simple and yet allows you to create and maintain a fleet
of crawlers, while not forcing too much specific process.
- Schedule crawlers to run at regular intervals (or run them ad-hoc as you need).
- Keep track of error messages and warnings that help admins see which crawlers are in need of maintenance.
- Lets you use familiar tools like
requests,BeautifulSoup,lxmlordatasetto do the actual scraping. - Distribute scraping tasks across multiple machines.
- Maintain an overview of your crawlers' status using the command line or a web-based admin interface.
For common crawling tasks, memorious does all of the heavy lifting. One
of our most frequent objectives is to follow every link on a large website and
download all PDF files. To achieve this with memorious, all you need to write
is a YAML file
that plugs together existing components.
Each memorious crawler is comprised of a set of different stages that call each
other in succession (or themselves, recursively). Each stage either executes a
built-in component, or a custom Python function, that may fetch, parse or store a
page just as you like it. memorious is also extensible, and contains lots of
helpers to make building your own custom crawlers as convenient as possible.
These configurable chains of operations have made our crawlers very modular, and common parts are reused efficiently. All crawlers can benefit from automatic cookie persistence, HTTP caching and logging.
Within OCCRP, memorious is used to feed documents and structured data into
aleph via an API, which means documents
become searchable as soon as they have been crawled. There, they will also
be sent through OCR and entity recognition. aleph aims to use these extracted
entities as bridges that link a given document to other databases and documents.
For a more detailed description of what memorious can do, see the
documentation and check out our
example project.
You can try memorious by running it locally in development mode,
and, of course, we also have a Docker setup for robust production deployment.
As we continually improve our crawler infrastructure at OCCRP, we'll be adding
features to memorious for everyone to use. Similarly, we'd love input from the data
journalism and open data communities; issues
and PRs are welcome.
“…the solitary and lucid spectator of a multiform, instantaneous and almost intolerably precise world…” (Funes the memorious, Jorge Luis Borges)
Manually deleting visits from Piwik by their IP (or URL, or...)
11.02.2016, by Aleksandar Todorović (r3bl)Piwik is an awesome self-hosted analytics service. We've been relying on it for a very long time and we were always satisfied with what it brought to us. During our work, however, we have accidentally allowed the traffic from our own servers to appear in Piwik, and some general traffic to be counted more than once, therefore we have accidentally boosted our own stats.
Now, since Piwik itself is open sourced, we see no reason why we should not be able to delete the artificially inflated stats ourselves and by doing so making sure that our journalists see the stats as precisely as possible.
Since the informations for this process were not as clear as we wanted them to be, I've decided to write this blog post so we could make the job easier to anyone else who tries to do the same. To follow this tutorial, you're going to need a Piwik installation (obviously), access to the command line on the server and some SQL-fu.
Step 1: Finding the records that you want to delete
This seems like a simple thing, but it turned out to be much harder. We had the list of couple of IP addresses that we wanted to exclude from Piwik, but after about half an hour of me searching through Piwik's interface, I was not able to find a way how to see the entire traffic that originated from a specific IP address. Luckily, I stumbled upon this short post which gave me every information I needed. To see the traffic from a specific IP, you have to manually tweak the URL you are visiting to:
https://piwik.example.com/index.php/?module=CoreHome&action=index&idSite=1&period=year&date=2016#module=Live&action=getVisitorLog&idSite=1&segment=visitIp==\{\{ IP ADDRESS GOES HERE \}\}
Bear in mind that Piwik shows 500 actions per visit as a maximum, so if the requested IP made over 500 actions in a single visit (for example, if it was a bot, or if somebody tried to scrape your website), you're only going to see the very first 500 actions that were requested by that IP.
Step 2: Finding and deleting records from the database(s)
The second step would be to find the records in the database as well. To do this for the IP you're interested in, you're going to have to convert the IP address to the HEX numeral system. Of course, everyone who finished two IT college courses should be able to convert the number to its HEX value by hand, but if you feel too lazy, just use this online tool to do so. Or use python:
print hex() # repeat for each IPv4 byte
Once you have the HEX equivalent of the IP in question, log into MySQL/MariaDB and execute the following command to get the count of rows (or: pageviews) that will be affected:
SELECT COUNT(*)
FROM piwik_log_visit AS log_visit
LEFT JOIN piwik_log_link_visit_action as log_link_visit_action
ON log_visit.idvisit = log_link_visit_action.idvisit
LEFT JOIN piwik_log_action as log_action
ON log_action.idaction = log_link_visit_action.idaction_url
WHERE log_visit.location_ip=UNHEX("\{\{ HEX_VALUE_GOES_HERE \}\}");
As you can see, Piwik stores the relevant visitor info into three separate MySQL databases: piwik_log_visit, piwik_log_link_visit_action and piwik_log_action.
If you skip one of them, you'll encounter some unexpected results. For example, initially, we've tried removing the data from piwik_log_visit and piwik_log_link_visit_action, but once we've re-computed the logs, we've noticed that the IP was still there and the visit time was still being shown, even though we have successfully deleted the actions associated with that visit.
0 Action - 42 min 59s
This is why it's important to delete the data from all three of the databases.
To delete the necessary entries from all the databases, you need to tweak the command above like this (for IP-based pruning):
DELETE log_visit, log_link_visit_action
FROM piwik_log_visit AS log_visit
LEFT JOIN piwik_log_link_visit_action as log_link_visit_action
ON log_visit.idvisit = log_link_visit_action.idvisit
LEFT JOIN piwik_log_action as log_action
ON log_action.idaction = log_link_visit_action.idaction_url
WHERE log_visit.location_ip=UNHEX("\{\{ HEX_VALUE_GOES_HERE \}\}");
You can verify that the visits/pageviews are gone from the db by using the SELECT statements again, of course.
Step 3: Re-compute the reports
If you have successfully completed the first two steps, your last step should be re-computing the reports. If you skip this step, you won't accomplish anything because the traffic will still be visible in the reports, even though the traffic has been removed from the databases.
To do so, I highly recommend you to take a careful look at Piwik's documentation. Specifically, you should pay a close attention to these two posts:
- How do I force the reports to be re-processed from the logs?
- How do I record tracking data in the past, and tell Piwik to invalidate and re-process the past reports?
Make sure that you invalidate data for the particular sites and dates affected, as processing time is directly dependant on this.
Bonus -- what about URLs?
Notice what we've put after the WHERE keyword in step number two. You can do all sorts of crazy thing there. For example:
[...] WHERE log_action.name LIKE 'example.com/wp-content/themes/%'
...will remove the traffic that hit the files associated with the WordPress theme you are using.
Keeping Your Android Secrets Out of Git
19.01.2016, by Christopher GuessDevelopers have a habit (one I've been guilty of) of committing API keys and other secrets to our repositories. It’s easy to do it if you’re tired, if you’re hurried, if you’re “moving fast and breaking things”.
This, unfortunately, has been too difficult to prevent for too long. In the interest of security there’s luckily been a big push to stop this practice lately; Rails has had the Figaro gem, but recently in version 4.1 they’ve built in a “secrets.yml” file. Heroku has a config ENV screen to /attempt/ to coerce developers into keeping secret keys out of production. Apple’s iOS and its keychain helps with this on iPhones and iPad.
As far as I’ve been able to tell, Android has been terrible at this.
I’ve scoured documentation, searched for hours across StackOverflow and questioned friends who are much better at Android that I am. After taking bits and pieces, I think I’ve figure a good way to do this. I’m probably not the first, but there doesn’t seem to be a comprehensive write up of this technique anywhere, so I'm hoping these steps help fellow Android devs up their security a bit.
Note: this does not secure credentials in the wild. It will not stop someone from decompiling your ADK and pulling the string. Everything ends up in the compiled app. What it does do is keep someone from going through your Github account and copy/pasting your secrets out of it.
Note: For these steps I’m assuming you’re using Android Studio.
Recognize what needs to be kept secret.
- Anything that’s unique to your deployment of the software.
- If you use a key for Google Analytics, or if you keep have an encryption key that needs to be hardcoded, these should never be committed to a repository.
- Don’t put these into the source code, ever, even for brief testing purposes.
Create a Gradle file just for your keys
- In Android Studio’s Project Navigator expand your “Gradle Scripts” drop down.
- Right click anywhere below the “Gradle Scripts” icon and hover over “New” and then click “File”.
- Name this file “safe_variable.gradle” (or whatever you want, just make note of it if it’s different).
Add this file to your .gitignore.
We don’t want to accidentally add it to the repository so add the following line the bottom of your .gitignore file in the project:
/app/safe_variables.gradle
Commit your .gitignore file
git commit .gitignore -m “Added secrets file to git ignore”- Add your keys to the new secrets file.
- This example uses two modes, debug and production. The names of the keys are arbitrary and you can put in whatever you need to keep secret.
buildTypes { debug{ resValue "string", "server\_url", "https://dev.example.com" resValue "string", "hockey\_key", "\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*" } release { resValue "string", "server\_url", "https://production.example.com" resValue "string", "hockey\_key", "\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*" } } //This line is only necessary if your app is using localization files for the strings. //There doesn't seem to be a way to add the strings to multiple langauges from Gradle. lintOptions { disable 'MissingTranslation' } Include this file into your Gradle file
On the “build.gradle (Module: app)” file, add the following line right after the “android” block
apply from: 'safe_variables.gradle', to: android
Commit your project again
- Build your project
- “Build” menu -> “Make Project”
- This will automatically add the files to compiled variable so you can reference it in your code.
Reference your API keys and other secrets where you need them.
- In an Activity you can reference it like so:
getResources().getString(R.string.server_url)In a fragment the following syntax can be used:
getActivity().getApplicationContext().getString(R.string.server_key)
That should do it. The only thing to remember is that if you’re switching machines or adding a new teammate they’ll have to recreate steps 2 and 5 on their machine as well.
If there’s an easier way to do this or perhaps a way to do it without having to turn off the translations error please feel free to get in contact at cguess@gmail.com or on Twitter at @cguess.
Migrating ElasticSearch across versions and clusters
13.01.2016, by Michał "rysiek" WoźniakMigrating data between ES clusters might seem like a simple thing -- after all, there are dedicated tools for that. Or one could use logstash with a simple config.
Things get a bit hairy, however, when the source and destination cluster versions differ wildly. Say, like 0.90.3 and 1.7.3. And when you don't happen to have any admin access to the source cluster (only via HTTP and transport interfaces).And when the source cluster is misconfigured in just a slight but annoying manner...
What did not work
elasticdump
ElasticDump was the first and obvious thing to try, but apparently it only supports migrations between clusters running ElasticSearch 1.2 and higher. So, that's a no-go.
logstash
Apparently one can use logstash to migrate data between clusters. Unfortunately this solution did not work, either.
What did work
Please keep in mind that this procedure worked for us, but it doesn't have to work for you. Specifically, if the source is a cluster of more than one node, you might need to do some fancy shard allocation to make sure that all shards and all indices are copied over to the new node.
1. Create a new node
Why not cluster with that source ES server (running a single-node cluster) by creating a new node that we do control, and thus get the data? Getting the docker container to run an ES version 0.90.3 was just a bit of manual fiddling with the Dockerfile. Changing the versions everywhere worked well, but here's hint: up until 1.0 or so, elasticsearch ran in background by default. Thus, the docker container stopped immediately after starting elasticsearch, for no apparent reason...
So if you're dealing with a pre-1.0 ES just add a -f (for "foregroud") to the command in Dockerfile to save yourself a bit of frustration.
2. Cluster with the source server
Once we have this running, it's time to cluster with the source node. What could be easier? Disable multicast discovery, enable unicast with a specified host and we're good, right?
Wrong. Remember the "misconfigured in just a slight but annoying manner" thing? The source IP server turned out to be behind a NAT and the IP that we could connect to differed from the IP the server published. Hence, our new node discovered the source node as master, but then -- based on the info gotten from it -- tried connecting to it via its internal (10.x.y.z) IP address. Which obviously did not work.
3. iptables to the rescue
As we had no way of changing the configuration of the source node, the only thing we could do was mangle the IP packets, so that packets going to 10.x.y.z would have the destination address modified to the public IP of the source node (and those coming from the public IP of the source node would get modified to have the source address of 10.x.y.z, but iptables handled that for us automagically):
iptables -t nat -I PREROUTING -d 10.x.y.z -j DNAT --to-destination <external_IP_of_the_source_node>
We love one-liners, don't you?
4. Get the data
Once we had this working and confirmed that the cluster is now two nodes (souce node and our new node), we just sat back and watched the ~9GiB of data flow in. Once that was done, it was time to down the new node, disabled discovery altogether, and up it again to verify that we now have the data in there, on a node that we actually control.
5. Upgrade
Full cluster restart upgrade is what we had to do next, but for our single-node cluster that's just a fancy way of saying:
- down the node;
- upgrade ES to whatever version needed (
1.7.3in our case); - up the node;
- verify everything is AOK.
6. Migrate the data to the production node
Since we were doing all this on a new node, created only to get the data off of the source ES 0.90.3 server, we needed to shunt the data off of it and into our production server (changing the index name in the process for good measure). This is where we turned back to elasticdump, and using a simple script were able to successfuly migrate the data off of the new node and onto our production ES 1.7.3 server.
Of course things could not got smooth and easy here, either. The dump kept being interrupted by an EADDRNOTAVAIL error; a quick work-around was to use the --skip command-line argument of elasticdump to skip rows that have already been migrated.
First Post
13.01.2016, by Smári McCarthyAround this time a year ago, OCCRP's Tech Team consisted of a single webmaster in Travnik and a few loyal friends who would be called upon to assist when new challenges arose. Since then, we've expanded to an excellent group of people, sitting mostly in Sarajevo and doing some pretty amazing things. This new blog is to tell you of our adventures.
We are working with a lot of different technologies, managing some legacy systems, building new software and making sense of a lot of structure. The core aim of all of our activities is simple: shorten the time to journalism (TTJ).
In practice, this means a lot of stuff, from the simple-looking task of making sure it's possible to publish stories, with whatever visuals and interactives are needed, to serving tools for sharing and collaboration between journalists, to constructing gadgets that allow journalists to work more effectively, and designing and building new systems that allow journalists to work better with large volumes of data.
On this blog we'll try to go a bit deeper into the thoughts of what we're doing and why, explaining our thought processes and announcing exciting progressions.
But first, some resources:
That's all for now. Watch this space!